
前言:
我們在先前的文章有提到,BigQuery 是一種無伺服器的資料倉儲(Serverless data warehouse),並且背後的編碼、加密和異地複製 Google cloud也都幫我們做好了,讓我們在使用上更方便不用動到底層;但是多了解 BigQuery 的基本架構,將有助於我們在操作上以及理解它的時候更有概念。
我們前面曾提到 BigQuery 的一個特點就是速度快,但是你有想過為什麼嗎?
其實就和 BigQuery 背後的架構有關!
BigQuery 基本架構:
先來一張 BigQuery 的架構長相,可以分為三大部分:
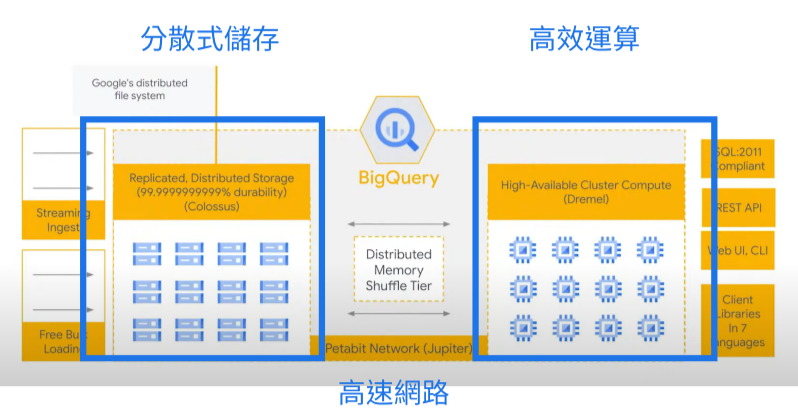
(1) Colossus: 我們可以想成就是BigQuery背後負責儲存資料的地方,是 Google 中的分散式儲存系統,並且是以 columnar storage format 儲存的,主要是受到 Hadoop file system (HDFS) 的啟發,身為 BigQuery 使用者,我們無法直接使用 Colossus,而是透過 SQL interface 來處理 data。
- columnar storage format: BigQuery 是以每一個欄位作為儲存,而不是像傳統的資
料庫那樣一列儲存,這樣儲存的形式非常有助於我們計算欄位的加總等等。
(2) Dremel: 我們可以想成就是BigQuery負責背後運算的地方,是 Google 內部的 SQL 分析工具。Dremel 根據需要動態地將槽分配給查詢,從而保持來自多個用戶查詢的公平性。 單個用戶可以獲得數千個slot來運行他們的查詢。
(3) Jupiter: 讓 Colossus(儲存) 和 Dremel(分析) 兩者溝通的高速網路,速度可達 PB/s。
BigQuery 資料存放地點:
那我們 BigQuery 的資料究竟存放在哪裡呢?
BigQuery 的資料會存放在使用者選擇的國家和城市,並且可以分為2種類型的位置:
(1) 單區域位置,例如 台灣 (asia-east (台灣))
(2) 多區域位置式至少包含 2 個 地理位置的大型地理區域,例如 美國 (US) 和 歐盟 (EU)
關於存放地點的幾點注意事項:
(1) 在創建數據集之後,我們選擇的位置便無法更改。
(2) 從 cloud storage 加載/匯出數據到 BigQuery 時。
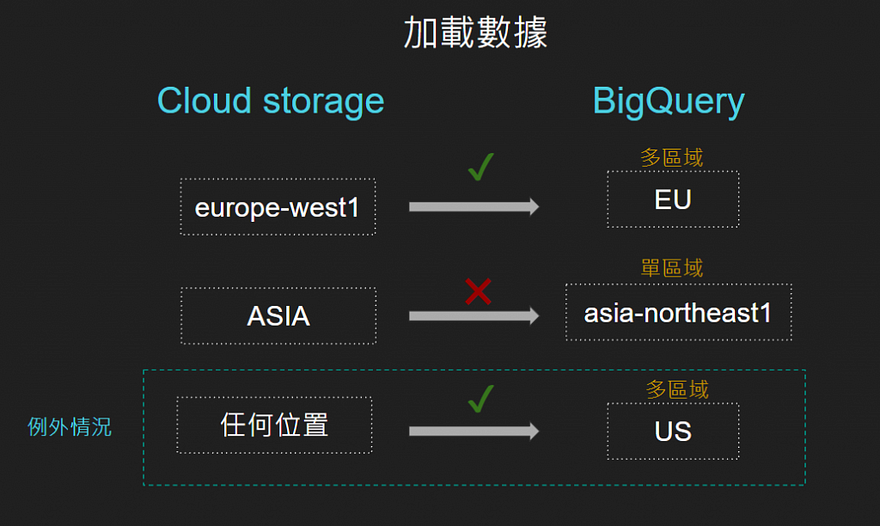
加載數據時:
BigQuery 數據集 位於多區域,則從cloud storage加載的存儲桶必須位於同一多區域或該多區域的位置。
BigQuery 數據集 位於某個區域,則 Cloud Storage加載的存儲桶必須位於同一區域。
匯出數據時:
BigQuery 數據集 位於多區域,則要導出的cloud storage 存儲桶必須位於同一多區域或該多區域的位置。
BigQuery 數據集 位於某個區域,則要導出Cloud Storage 存儲桶必須位於同一區域。
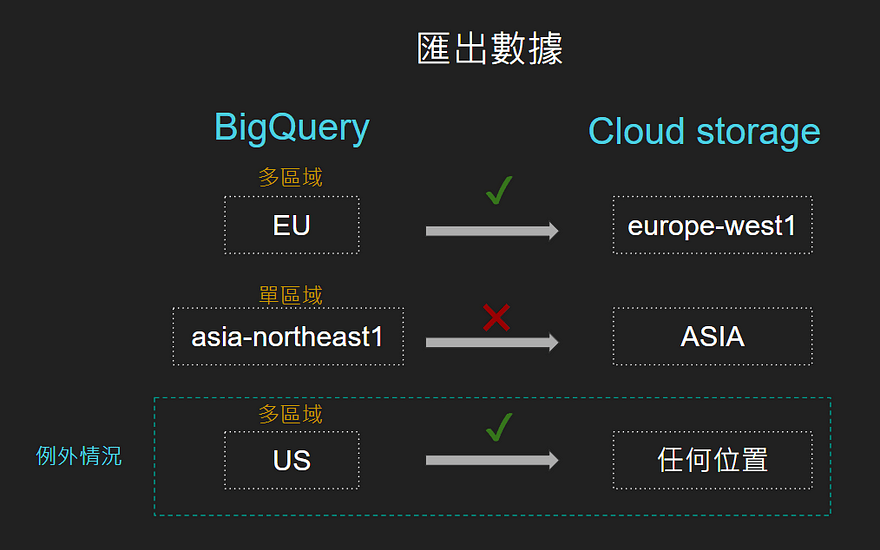
例外情況: 如果BigQuery數據集位於多區域 US,cloud storage可以位於任何位置。
(3) 最後還有一點需要注意的是,並非所有 GCP服務在每個區域都可以用,建議要到官方文件以了解可用性。
Summary:
(1) BigQuery 的架構可分為 Colossus(儲存), Dremel (運算) 和 Jupiter (高速網路) 三大部分。
(2) BigQuery 的資料是存在不同的國家和城市,使用上需注意儲存區域和地區,以確保相關的服務可以互相串接,而多區域 US 是例外情況。
Reference:
BigQuery explained: An overview of BigQuery’s architecture
Data locations

